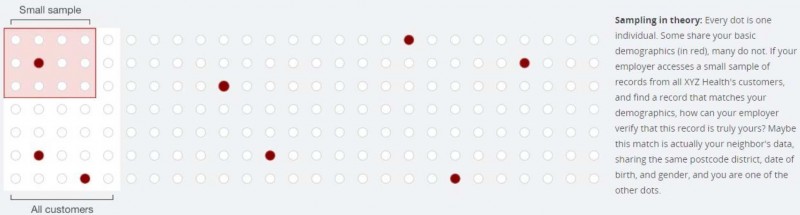
The tool explaining how sampling can help anonymise data
Current methods for anonymising data leave individuals at risk of being re-identified, according to new UCLouvain and Imperial research. Companies and governments downplay the risk of re-identification by arguing that the datasets they sell are always incomplete. Our findings show this might not help. Dr Yves-Alexandre de Montjoye Department of Computing/Data Science Institute With the first large fines for breaching EU General Data Protection Regulation (GDPR) regulations upon us, and the UK government about to review GDPR guidelines, researchers have shown how even anonymised datasets can be traced back to individuals using machine learning, a type of artificial intelligence. The researchers say their paper , published , demonstrates that allowing data to be used - to train AI algorithms, for example - while preserving people's privacy, requires much more than simply adding noise, sampling datasets, and other de-identification techniques. They have also published a demonstration tool that allows people to understand just how likely they are to be traced, even if the dataset they are in is anonymised and just a small fraction of it shared. The research team, led by Dr Luc Rocher of UCLouvain , says its findings should be a wake-up call for policymakers on the need to tighten the rules for what constitutes truly anonymous data.
TO READ THIS ARTICLE, CREATE YOUR ACCOUNT
And extend your reading, free of charge and with no commitment.