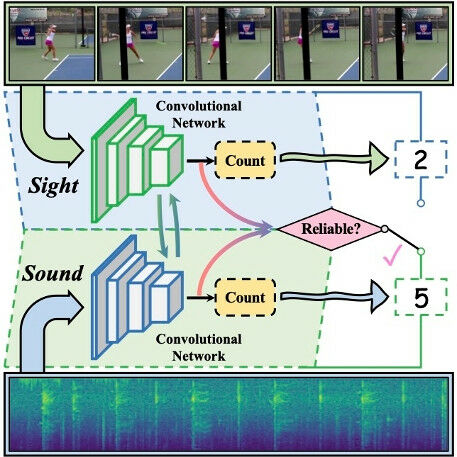
Figure 1: From sight and sound, as well as their cross-modal interaction, the number of repetitions for an (unknown) activity happening in a video is predicted. There are two streams, and each stream processes each modality with a convolutional neural network. The reliability estimation module finally decides what prediction from which modality to use, according to the perceived quality of each modality.
Figure 1: From sight and sound, as well as their cross-modal interaction, the number of repetitions for an (unknown) activity happening in a video is predicted. There are two streams, and each stream processes each modality with a convolutional neural network. The reliability estimation module finally decides what prediction from which modality to use, according to the perceived quality of each modality. Counting repetitive phenomena by the use of sight and sound 28 June 2021 Recently, an article from researchers from the Informatics Institute of the University of Amsterdam has been published at the IEEE Conference on Computer Vision and Pattern Recognition; the leading peer-reviewed publication venue in the field of artificial intelligence. The researchers introduced a method for counting repetitions, which are relevant when analyzing human activity (sports), animal behavior (a bee's waggle dance) or natural phenomena (leaves in the wind) by integrating for the first time the audio modality in a visual counting system based on neural networks. VIS) , in collaboration with Ling Shao from the Inception Institute of Artificial Intelligence ( IIAI ), developed a method for estimating how many times a certain repetitive phenomenon, such as bouncing on a trampoline, slicing an onion, or playing ping pong, happens in a video stream. Their methodology is applicable to any scenario in which repetitive motion patterns exist.
TO READ THIS ARTICLE, CREATE YOUR ACCOUNT
And extend your reading, free of charge and with no commitment.