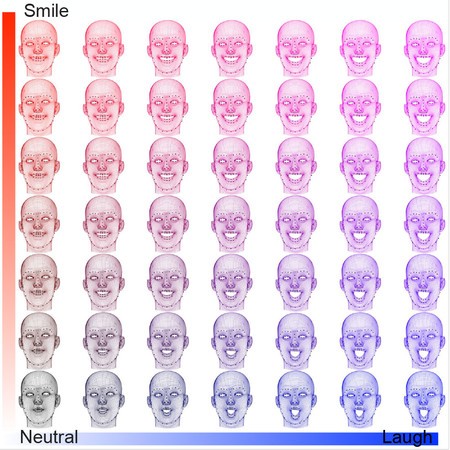
Yue's variational autoencoders translate images of faces into sets of numerical data using machine learning.
Engineers have created a new deep-learning software capable of assessing complex audience reactions to movies using the viewer's facial expressions. Developed by Disney Research in collaboration with Yisong Yue of Caltech and colleagues at Simon Fraser University, the software relies on a new algorithm known as factorized variational autoencoders (FVAEs). Variational autoencoders use deep learning to automatically translate images of complex objects, like faces, into sets of numerical data, also known as a latent representation or encoding. The contribution of Yue and his colleagues was to train the autoencoders to incorporate metadata (pertinent information about the data being analyzed). In the parlance of the field, they used the metadata to define an encoding space that can be factorized. In this case, the factorized variational autoencoder takes images of the faces of people watching movies and breaks them down into a series of numbers representing specific features: one number for how much a face is smiling, another for how wide open the eyes are, etc. Metadata then allow the algorithm to connect those numbers with other relevant bits of data-for example, with other images of the same face taken at different points in time, or of other faces at the same point in time.
TO READ THIS ARTICLE, CREATE YOUR ACCOUNT
And extend your reading, free of charge and with no commitment.